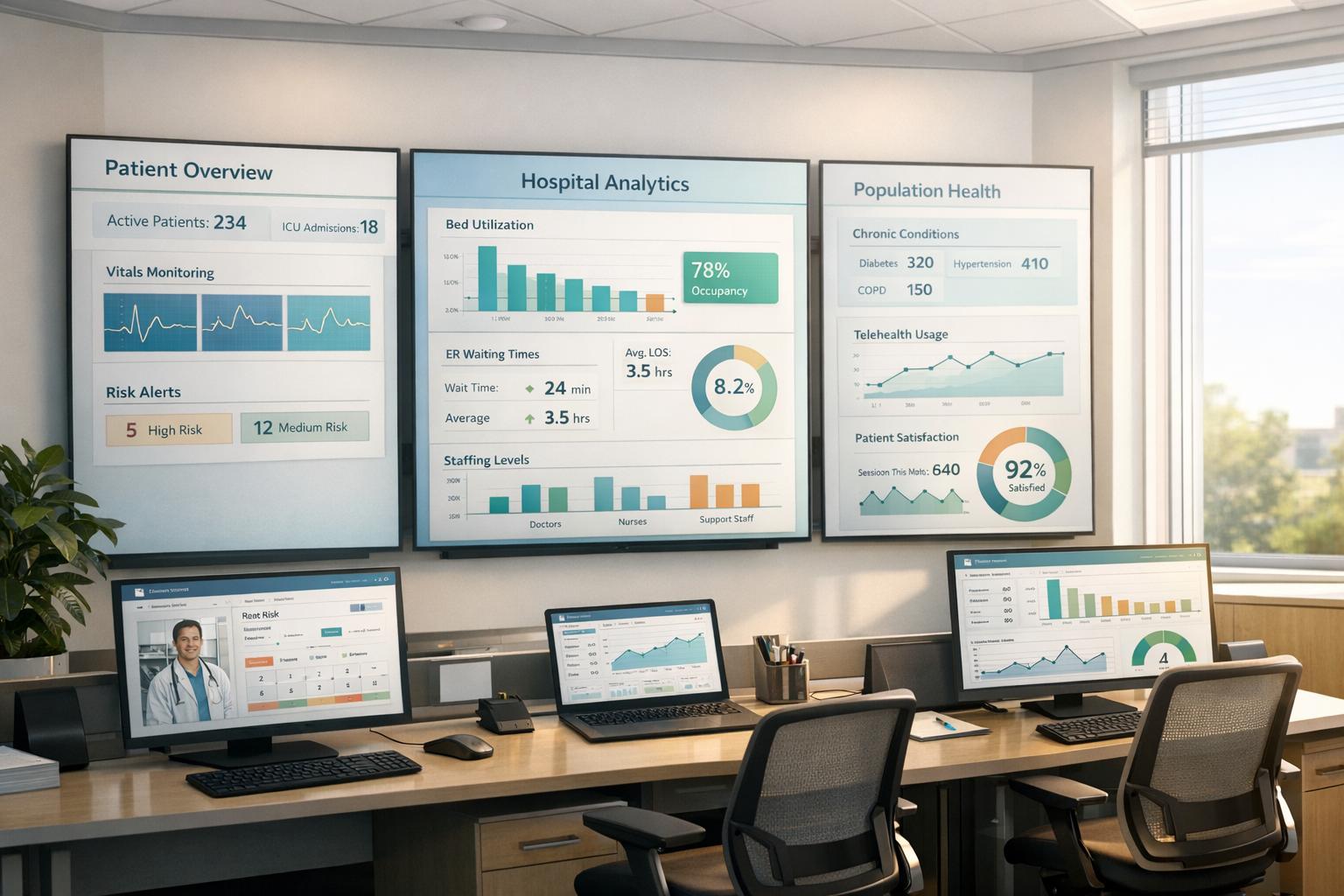
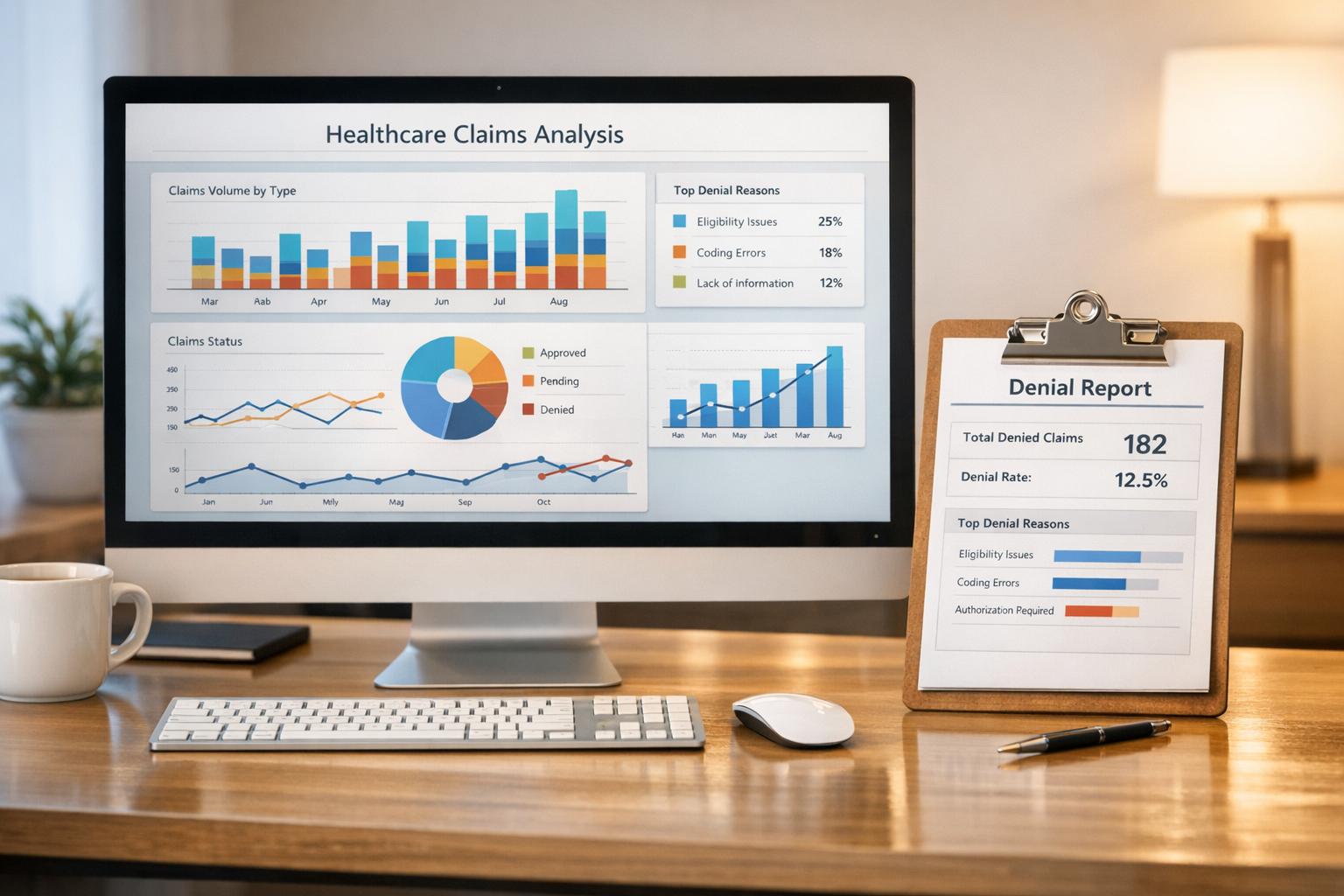
Explore the impact of AI bias in healthcare, its sources, consequences, and effective strategies for promoting fairness and equity in patient care.
AI bias in healthcare can lead to unequal treatment, harm patient trust, and worsen existing disparities. Here's what you need to know:
Addressing bias isn't just about compliance; it's about ensuring equitable, reliable care for all patients.
The backbone of any AI system is its training data. When that data is flawed or incomplete, the entire system can falter, leading to unreliable results. In healthcare, data source bias poses a major challenge, threatening fair and effective patient care. These biases in data collection lay the groundwork for many of the issues AI systems face.
Data source bias happens when the training data doesn't fully reflect the diversity of patients, causing AI systems to work well for some groups while failing others.
In the U.S., gaps in geographic, demographic, and socioeconomic representation - such as the underrepresentation of rural, low-income, and non-English-speaking patients - skew the data. This issue is especially problematic when AI systems are trained on data from limited healthcare networks. For example, data from large academic hospitals may not translate well to community hospitals or rural clinics, where patient populations and coding practices differ significantly.
Language barriers also play a role. Non-English-speaking patients often have less detailed medical records, which can hinder an AI system's ability to provide accurate recommendations for these groups.
Another challenge is the impact of time. Healthcare practices evolve, and historical data can become outdated. AI systems trained on older datasets may end up offering recommendations that no longer align with current medical standards.
These issues in data collection not only skew AI outputs but also create serious risks, particularly when training relies on incomplete claims data.
Claims data, used for insurance verification and treatment approvals, contains built-in biases that can amplify existing health disparities when used to train AI models.
For instance, claims data often reflects historical discrimination. If AI systems learn from this biased data, they may inadvertently perpetuate the very inequities that healthcare providers are working to eliminate.
Variations in insurance coverage and coding practices also create discrepancies. Patients with consistent insurance and regular access to care tend to have more complete claims histories. On the other hand, those with intermittent coverage or limited access generate fragmented records, putting them at a disadvantage when AI systems favor more extensive datasets.
Patients who pay out-of-pocket or have restricted data sharing often fall through the cracks, leaving AI systems unprepared to address their needs. This gap means that when these patients do interact with the healthcare system, the AI may struggle to make accurate recommendations.
Other factors, like the underrepresentation of emergency care data and differences in payment models, further complicate training. Emergency care often involves unique documentation patterns, while payment structures like fee-for-service versus value-based care influence how services are recorded and billed. These inconsistencies can lead to AI systems making inappropriate recommendations or decisions.
Ultimately, these data shortcomings have a direct impact on patient care, reinforcing concerns about biased AI in healthcare.
AI systems in healthcare can unintentionally create disparities in outcomes, influencing both the quality of care and access to it. These disparities often arise from subtle patterns in the data and algorithms, which can amplify existing inequalities.
The ripple effect of these biases goes beyond individual patients - it can affect entire communities. When AI tools consistently underperform for certain groups, they risk exacerbating existing health inequities and creating additional barriers to fair and effective care.
Biases in AI systems can stem from a variety of sources, including geographic data, socioeconomic factors, and technical limitations. For example, using zip codes to predict risks or recommend treatments can unintentionally embed socioeconomic inequalities into the system. In areas with higher poverty levels, limited healthcare facilities, or environmental risks, algorithms may flag residents as "high-risk." This can lead to different treatment recommendations or increased scrutiny, regardless of the actual health needs of the individuals.
Technical biases are another concern. AI systems trained primarily on lighter-skinned images often fail to perform as accurately for patients with darker skin tones. This can result in delayed or incorrect diagnoses, potentially worsening health outcomes for these patients.
Insurance status can also influence AI predictions. Systems may associate certain types of insurance with specific risk profiles, leading to variations in treatment recommendations. Similarly, when training data underrepresents certain age groups, older adults may receive less aggressive treatment suggestions due to age-related biases in the algorithm.
Language barriers and cultural differences further complicate matters. AI systems that depend on detailed patient histories or specific medical terminology can falter when dealing with incomplete records caused by language differences or variations in how symptoms are described. These gaps in communication can reduce the accuracy of AI recommendations.
To address these challenges, it's essential to have precise methods for identifying and addressing bias in AI systems.
To combat these disparities, healthcare organizations need to closely monitor AI performance across all demographic groups. Establishing baselines and consistently tracking outcomes is key to spotting bias early.
Monitoring involves evaluating metrics such as diagnostic accuracy, treatment recommendations, and patient satisfaction across different groups - defined by factors like race, ethnicity, age, gender, insurance type, and geographic location. If significant performance gaps between groups are identified, they signal potential biases that require further investigation.
Regular audits are essential to ensure disparities don’t become entrenched. These audits assess both the accuracy of AI predictions and the real-world outcomes experienced by various demographic groups. For example, examining differences in false positive and false negative rates, treatment patterns, and predicted risk scores can highlight areas of concern. Additionally, tracking indirect impacts - such as wait times, referral patterns, and satisfaction scores - can provide a more comprehensive picture of AI's effects.
Long-term analysis is particularly valuable for understanding whether disparities are growing or shrinking. This approach also helps in evaluating the effectiveness of bias mitigation strategies. Intersectionality - how multiple demographic factors like age and gender overlap - should also be considered. For instance, an AI system might perform well for women overall and for older adults in general, but still struggle to deliver accurate results for older women specifically.
To support these efforts, robust documentation and standardized reporting practices are crucial. By systematically recording demographic data and analyzing AI performance, healthcare organizations can not only meet regulatory requirements but also drive continuous improvement in equitable care delivery.
Once disparities are identified, organizations need to take proactive steps by conducting audits and implementing strategies to reduce bias. Tackling bias effectively means combining systematic evaluations with practical interventions tailored to specific healthcare environments and AI applications.
The success of bias reduction hinges on blending thorough auditing processes with actionable strategies. This approach ensures that organizations not only uncover problems but also have the tools to address them in a structured way. Let’s explore how audits and reduction methods work together.
Bias audits are the cornerstone of any bias reduction initiative. The process starts with defining clear evaluation criteria, moving beyond basic accuracy metrics to assess how AI systems perform across different demographic groups and clinical scenarios.
Pre-deployment audits take place before AI systems are introduced into clinical settings. These audits involve testing models with diverse datasets to evaluate prediction accuracy, recommendation patterns, and decision thresholds across various demographic groups. Auditors also check whether the training data reflects the diversity of the target population, identifying any gaps that could lead to biased outcomes.
Post-deployment monitoring ensures ongoing oversight once AI systems are in use. This involves tracking real-world performance metrics, patient outcomes, and user feedback to continuously evaluate how the system performs across different demographic groups.
The audit process also includes stakeholder interviews to gather insights from healthcare providers, patients, and administrative staff who interact with the AI system. For example, nurses might observe that certain groups of patients receive differing treatment recommendations, while patients may feel the system doesn’t fully account for their unique health needs.
Documentation and reporting are critical for transparency and accountability. Organizations must record audit findings, including examples of bias and the groups affected. This documentation not only supports compliance with regulations but also serves as a benchmark for tracking improvements over time.
Once audits pinpoint areas of bias, targeted strategies can be applied to address them effectively.
Audit findings inform the selection of strategies to reduce bias. The most effective approaches combine technical solutions with organizational changes to tackle the root causes of bias.
Data diversification is a foundational strategy. Expanding training datasets to include underrepresented groups, geographic regions, and clinical scenarios ensures AI systems are exposed to a broader range of patient experiences. Partnerships between institutions to share anonymized data can help achieve this. Additionally, organizations can implement data collection protocols that specifically address representation gaps, such as recruiting diverse participants for clinical studies or ensuring imaging datasets include patients with varying skin tones.
Algorithmic adjustments offer technical solutions for mitigating bias in decision-making processes. Techniques include adjusting decision thresholds for specific demographic groups, applying fairness constraints during model training, or using ensemble methods to combine multiple algorithms, thereby reducing individual model biases. Adversarial debiasing, where supplemental algorithms counteract bias in the main model, is another effective approach.
Human oversight integration ensures that critical decisions, especially those affecting vulnerable populations, involve human review. This could mean requiring human approval for specific treatment recommendations, implementing escalation procedures when AI confidence is low, or providing healthcare providers with additional context about potential bias risks for certain patient groups.
Continuous feedback loops create systems for ongoing detection and correction of bias. These mechanisms collect data on AI performance, patient outcomes, and user experiences, using the information to refine algorithms and address emerging bias patterns. Retraining models with new data helps correct identified biases, while feedback from healthcare providers enhances the system’s effectiveness in real-world scenarios.
Transparency and explainability are essential for helping healthcare providers understand how AI systems make decisions. Clear explanations of why certain treatments are recommended, along with the factors influencing those decisions, enable providers to evaluate AI outputs critically. Offering alternative options when appropriate further empowers providers to intervene if bias is suspected.
Cross-functional bias review teams bring diverse perspectives to the table. These teams typically include clinical staff, data scientists, ethicists, patient advocates, and representatives from affected communities. By working collaboratively, they can identify biases that might be overlooked in purely technical evaluations and ensure that reduction efforts align with patient needs and clinical best practices.
When it comes to reducing bias in AI systems, organizations must strike a balance between technical effectiveness and resource limitations. Tackling bias often involves a mix of approaches aimed at addressing both underlying biases and specific error patterns.
Fairness metrics play a key role in evaluating these strategies. Research highlights that group fairness is the most commonly assessed metric, appearing in 93.1% of studies (79.5% of which use performance metrics). In comparison, individual fairness and distribution fairness are far less frequent, showing up in just 4.3% and 3.9% of studies, respectively. Meanwhile, calibration performance - an essential measure for ensuring accuracy across different groups - was noted in only 3.2% of studies. These metrics serve as a foundation for selecting the right bias reduction methods.
To address bias effectively, organizations need to align their resources, staff expertise, and compliance with regulations. For example, data diversification is a powerful way to tackle bias at its root. While it can be costly upfront, this approach minimizes bias by enriching datasets with more representative samples. On the other hand, algorithmic adjustments - when paired with human oversight - can help mitigate unexpected errors. This method may require ongoing effort but provides a flexible way to adapt to evolving challenges. Additionally, regulatory requirements push organizations to ensure their AI systems are transparent and interpretable, adding another layer of accountability.
Addressing bias in healthcare AI is essential to ensure these systems serve all patients fairly. When biases go unchecked, they lead to inequitable outcomes that can undermine the benefits of healthcare automation.
To tackle these challenges, several key strategies are vital. Diversifying data ensures training datasets reflect the diversity of patient populations. Meanwhile, incorporating algorithmic adjustments with human oversight helps safeguard against unexpected errors. Together, these steps not only improve accuracy but also build trust among patients and providers.
Healthcare organizations need to see the development of fair AI systems as an investment - not just in technology but in long-term effectiveness and patient trust. When AI systems consistently provide accurate results for all demographics, they become reliable tools that healthcare professionals can embrace with confidence. This reliability leads to smoother operations and better outcomes for patients.
At MedOps, we integrate comprehensive bias mitigation into our AI solutions, focusing on equitable insurance verification and workflow optimization. By emphasizing transparency, regular audits, and ongoing improvements, we aim to create AI systems that healthcare providers can rely on to improve both patient care and operational efficiency.
The success of healthcare automation depends on getting this right. Fair AI isn't just about meeting ethical or regulatory standards - it’s about building systems that deliver for everyone, strengthening the entire healthcare system in the process.
Healthcare organizations can take meaningful steps to promote equity in AI by prioritizing diverse and representative data when developing systems. This approach helps minimize the risk of bias that can arise from datasets that don't adequately reflect all patient groups.
Conducting regular bias audits is another critical measure. These audits help identify and address any disparities that might affect the quality of patient care, ensuring the system serves everyone fairly.
Beyond data, designing algorithms with inclusivity in mind and adopting bias mitigation frameworks can make a significant difference. These strategies aim to create AI systems that deliver fair and equitable care to all, helping to build trust and improve health outcomes for a wide range of populations.
To make sure AI training data mirrors the diverse patient populations in the U.S., it's crucial to gather information from a broad range of sources, including communities that are often overlooked or underserved. Partnering with groups like patient advocacy organizations and local community groups can be a great way to pinpoint where representation might be lacking.
Another useful approach is leveraging data augmentation techniques to generate synthetic examples of underrepresented groups, which can help create a more balanced dataset. Regularly auditing and updating these datasets is equally important. This process helps uncover and address biases, ensuring the AI remains fair and effective for all patient groups. These efforts play a key role in reducing disparities and supporting equity in AI-powered healthcare solutions.
Language barriers and socioeconomic challenges can skew healthcare AI systems by affecting the quality and diversity of the data used to train them. For instance, individuals with limited English skills or lower income often face reduced access to healthcare services, which means they may be underrepresented in the datasets. This lack of representation can result in AI systems producing less accurate or even biased recommendations for these populations.
Addressing this issue starts with gathering data that truly represents all patient groups, ensuring no one is left out. AI models should be built with fairness and transparency as core principles, drawing on insights from a broad range of stakeholders. Additionally, ongoing monitoring and regular updates are essential to spot and correct biases, helping create systems that work fairly for everyone.