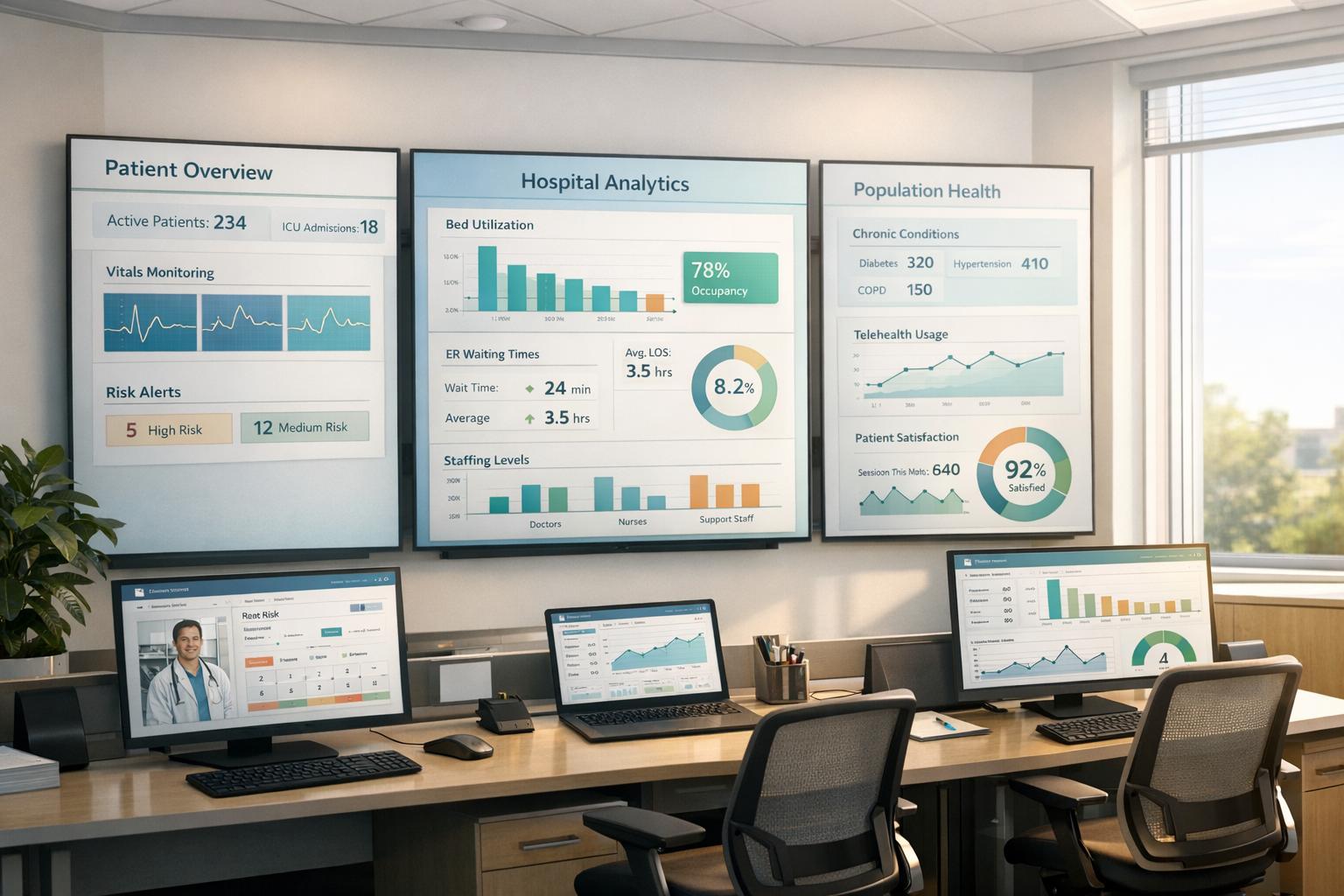
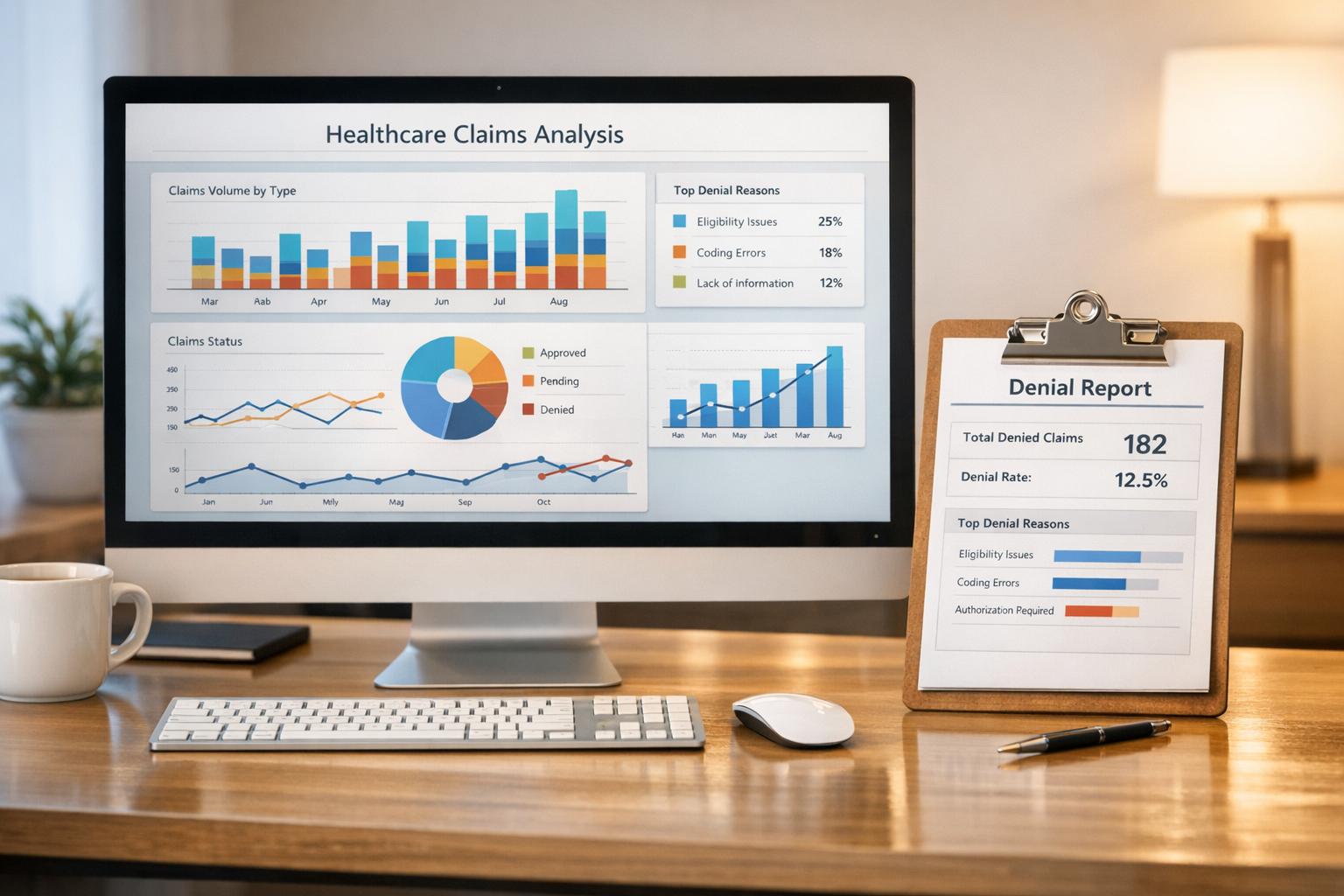
Explore how machine learning streamlines data cleaning in healthcare, improving accuracy, efficiency, and patient outcomes.
Managing healthcare data is challenging, but machine learning simplifies the process. With over 30% of the world’s data coming from healthcare, ensuring accuracy in patient records is critical. Data errors cost billions annually and impact patient safety. Machine learning automates cleaning tasks, detects anomalies, and reduces inaccuracies by up to 60%, saving time and improving outcomes.
Machine learning tools like MedOps streamline data cleaning, reduce manual effort, and ensure compliance with regulations like HIPAA. This technology supports better decision-making and allows healthcare professionals to focus on patient care.
Machine learning has revolutionized data cleaning by automating the process of detecting both predictable errors and unexpected anomalies. These methods not only address known issues but also reveal hidden irregularities, paving the way for more targeted and effective data cleaning.
Supervised learning is particularly effective when examples of clean and erroneous data are available. By training on labeled datasets - where correct and incorrect entries are clearly identified - these models can detect and correct similar issues in new data. For instance, error rates in healthcare data can reach up to 27% in certain scenarios.
The real strength of supervised learning lies in its ability to predict missing values and standardize inconsistent entries. Algorithms like Naive Bayes, linear regression, and support vector machines are often employed to handle tasks such as filling gaps or correcting formatting errors. Imagine a scenario where patient weight data is missing - these models can estimate plausible values based on factors like age, height, and medical history.
To ensure accuracy, structured training is key. This involves carefully selecting, labeling, and partitioning data. Regular updates and monitoring are also essential to adapt the model to evolving data patterns.
"Supervised learning is a machine learning technique that uses human-labeled input and output datasets to train artificial intelligence models." - IBM
AI-powered real-time error detection has shown impressive results, with the potential to reduce inaccuracies by as much as 60%.
Next, let’s look at how unsupervised learning tackles anomalies without requiring pre-labeled datasets.
When labeled data isn’t available, unsupervised learning steps in as an effective tool for anomaly detection. These algorithms specialize in identifying unusual patterns or outliers that could signal data quality problems. For example, clustering methods like DBSCAN (Density-Based Spatial Clustering of Applications with Noise) can highlight records that deviate significantly from typical patterns.
The process begins with data preprocessing, where features are filtered and enhanced to prepare them for anomaly detection. Techniques like categorical embeddings - such as Latent Semantic Analysis - are particularly useful for handling complex categorical variables, like diagnostic codes in healthcare, which often include thousands of unique classifications. Additionally, summarizing time series data using metrics like mean, sum, and standard deviation provides valuable context for analysis.
A compelling example comes from the Christian Health Insurance Fund in Belgium. Researchers combined categorical embeddings with anomaly detection techniques to analyze health insurance data, uncovering unusual trends among general practitioners related to orthopedic surgeries. These insights might have otherwise gone unnoticed.
Explainability tools like SHAP (Shapley Additive Explanations) play a crucial role here, helping experts understand why certain data points are flagged as anomalies. This ensures that flagged irregularities are carefully evaluated and not dismissed without proper review.
With these methods in place, continuous learning can take data quality improvement to the next level.
Healthcare data evolves rapidly, and static models can quickly become outdated. Continuous learning addresses this challenge by enabling AI systems to update incrementally as new data becomes available. This approach prevents data obsolescence while enhancing the system’s ability to recognize patterns over time. Compared to retraining models from scratch, incremental updates are more efficient and resource-friendly.
In healthcare, continuous learning has been applied to tasks like predicting disease outbreaks and improving patient health outcomes. For data cleaning, this means systems can learn from corrections made by healthcare staff, gradually becoming more effective at spotting and fixing errors.
The WUPERR (Weight Uncertainty Propagation and Episodic Representation Replay) study highlighted the benefits of continuous learning, showing that these methods maintained higher predictive accuracy compared to traditional transfer learning approaches.
To implement continuous learning successfully, organizations need to track performance metrics, use diverse and high-quality data, and provide regular feedback to refine models. This not only enhances data accuracy but also delivers business advantages - companies have reported up to 40% higher revenue through improved personalization efforts. By adopting this dynamic approach, healthcare organizations can ensure their data remains accurate and relevant in an ever-changing landscape.
Now that you're familiar with the machine learning methods available, let’s explore how they can be applied in real-world scenarios. Healthcare organizations, in particular, can use these techniques to address persistent data quality issues and simplify everyday operations.
Missing data is one of the biggest hurdles in healthcare data management. Machine learning tackles this issue through predictive imputation, a technique that fills in missing values by analyzing relationships between variables. The process typically starts with a data quality audit to pinpoint incomplete areas, which then allows for the creation of targeted AI models. For instance, if electronic health records lack patient weight information, a predictive model could estimate these values using factors like age, height, and other clinical data. Compared to traditional methods, advanced machine learning significantly improves accuracy.
AI tools take this a step further by automating data collection from various sources, minimizing manual input errors and creating more complete datasets. This automation lays the groundwork for additional tasks like deduplication and standardization, saving time and improving reliability.
Duplicate entries are more than just an inconvenience - they can undermine data integrity and lead to costly errors. In fact, data quality issues cost U.S. businesses over $600 billion annually. To detect and resolve duplicates, healthcare organizations often start by cleaning and standardizing their records. Techniques like phonetic matching, fuzzy matching, and clustering algorithms are commonly used to identify near-duplicate entries.
For example, one hospital employed DBSCAN clustering to group similar records based on patient names, birth dates, and addresses. Machine learning models that incorporate fuzzy matching scores can further refine this process. Once duplicates are identified, organizations can implement automated rules to retain the most complete and accurate records. Regular audits help maintain this high level of data integrity. After resolving duplicates, standardizing data formats ensures smooth integration and consistency across systems.
Once missing and duplicate data have been addressed, the next challenge is to unify data formats. Healthcare data comes from a variety of systems, and standardization is essential for seamless integration. Machine learning models can transform inconsistent formats - such as payer inputs, dates, and currencies - into a uniform structure, making the data more consistent and usable.
For example, machine learning can automatically identify and convert various date formats (like DD/MM/YYYY or YYYY-MM-DD) into the U.S. standard, MM/DD/YYYY. Similarly, financial data can be adjusted to display amounts as $1,234.56, ensuring proper formatting with commas and decimals. Medical documentation can also be aligned using standardized coding systems like ICD-10 and CPT.
Advanced AI and natural language processing (NLP) tools further streamline this process by spotting and fixing inconsistencies automatically, improving the reliability of datasets. Additionally, FHIR (Fast Healthcare Interoperability Resources) implementations enable real-time data exchange between applications, supporting features like patient portals while maintaining consistent formats. As Kim Perry, Chief Growth Officer at emtelligent, puts it:
"By breaking down this final barrier in the clinical data pipeline, the healthcare industry can unlock the true value of its investment in digital health technology, ultimately transforming patient care and outcomes."
Finally, integrating standardized data across large electronic medical record systems ensures smooth cross-platform data exchange, creating a unified and efficient data environment.

MedOps offers AI-driven solutions designed to clean healthcare data and streamline workflows. By applying advanced machine learning techniques, MedOps provides real-time, scalable tools to tackle critical data quality issues. From eliminating duplicate patient records to standardizing inconsistent data formats, the platform helps healthcare providers maintain a compliant and efficient data infrastructure in line with U.S. healthcare regulations.
MedOps uses cutting-edge machine learning (ML) algorithms to address persistent data challenges in healthcare. For instance, its duplicate detection system follows a four-step ML process to resolve patient identities, cutting duplication rates to as low as 1%. This is a significant improvement, considering duplication rates can climb as high as 30% in some organizations, with an average rate of 10%.
The platform also offers real-time validation to prevent the creation of duplicate records, reducing errors by 60%. Dr. Oleg Bess, Co-founder and CEO of 4medica, highlights this capability:
"Machine learning not only clears up duplicate records, it also prevents their creation by analyzing all fields in a medical record database and matching the results and signifiers to the correct patient before the record is finalized."
MedOps integrates seamlessly with Electronic Health Record (EHR) systems, enhancing data management through automated data capture and error detection. Its AI-powered monitoring tools ensure healthcare organizations remain compliant with regulations while safeguarding sensitive patient information. Additionally, the platform automates repetitive tasks using Robotic Process Automation (RPA), employs predictive analytics for better decision-making, and supports integration with large EMR systems.
These capabilities significantly enhance operational efficiency and data reliability for healthcare providers.
The financial toll of poor data quality in healthcare is immense. Duplicate patient records alone can cost around $2,000 per inpatient stay and $800 per emergency department visit. Furthermore, one-third of claims denials are linked to errors in patient identification or health data. MedOps tackles these issues by reducing manual workloads and improving accuracy with AI-driven error detection, which cuts data inaccuracies by 60%.
Automated workflow optimization is another key benefit. By implementing AI-powered data management, healthcare organizations have reallocated the equivalent workload of two to five full-time employees who were previously focused on provider data exchange. This shift reduces billing errors and speeds up care delivery.
By ensuring accuracy from the outset, MedOps helps healthcare organizations minimize costly denials and improve patient outcomes.
MedOps is designed to grow alongside your organization, offering tailored solutions that scale to meet evolving needs. The implementation process begins with a thorough data quality audit to pinpoint weaknesses and assess specific organizational requirements.
Its scalable architecture allows organizations to start with pilot projects and expand to full-scale deployment. MedOps provides interoperable AI tools that adapt over time, ensuring long-term value. The process includes staff training and continuous monitoring to maintain peak performance.
| Implementation Best Practices | Key Considerations |
|---|---|
| Pilot projects | Test feasibility and measure impact before scaling |
| Data privacy compliance | Adhere to HIPAA and other regulatory standards |
| Staff training | Equip teams with the knowledge to maximize benefits |
| Targeted solutions | Focus on specific data quality issues for measurable results |
| Human oversight | Combine AI automation with clinical expertise |
MedOps follows a custom pricing model, allowing healthcare organizations to get solutions tailored to their operational needs and budgets. Its seamless integration with existing systems minimizes disruptions during implementation while maximizing the impact of AI-powered data cleaning across the organization.
In the US healthcare system, effective data cleaning isn't just about maintaining order - it's about saving lives and ensuring compliance. With 85% of healthcare organizations experiencing data breaches and the average breach costing a staggering $10.93 million, following strict protocols is non-negotiable. Data errors alone contribute to an estimated 100,000 lives lost annually. One of the first steps to addressing this is standardizing data formats to promote consistency and smooth communication across systems.
Ensuring uniformity in data formats is critical for the US healthcare industry. This includes adopting standards like MM/DD/YYYY for dates, US dollars ($) for currency, imperial units (pounds, inches) for measurements, Fahrenheit for temperatures, and the (XXX) XXX-XXXX format for phone numbers. Such standardization not only improves data consistency but also simplifies interoperability.
To further enhance accuracy, healthcare organizations should use standardized coding systems such as ICD-10, CPT, and SNOMED CT. Adopting frameworks like SNOMED CT and FHIR facilitates seamless data exchange between systems and ensures reliability. These measures also enhance the performance of machine learning tools used in data cleaning, especially in medical operations.
Electronic Health Record (EHR) systems play an essential role here by streamlining data entry and minimizing manual errors. They ensure data is captured consistently across platforms. Real-time validation features in EHRs can flag formatting errors as they occur, while unique identifiers help prevent duplicate records.

Compliance with HIPAA regulations is a cornerstone of healthcare data management. Protecting electronic protected health information (ePHI) requires a multi-layered approach involving administrative, physical, and technical safeguards.
Violating HIPAA can lead to severe financial and legal consequences, with fines ranging from $100 to $1.5 million and criminal penalties that include up to $250,000 in fines and 10 years of imprisonment. Additionally, organizations must establish Business Associate Agreements (BAAs) with any vendors handling PHI to maintain compliance across the entire data ecosystem.
High-quality data is the backbone of effective healthcare operations. Regular audits and systematic validation are essential for maintaining accuracy. Automated tools can identify and merge duplicate records, while machine learning algorithms are especially adept at spotting anomalies and potential issues.
Clear data governance policies are crucial. These should define roles, responsibilities, and procedures for ensuring data quality. Automated checks and routine quality assessments provide continuous oversight, while standardized data entry processes and ongoing staff training help reduce errors and maintain consistency.
Collaboration between healthcare professionals and technical teams is vital. Unified data governance platforms make it easier to manage data throughout its lifecycle, ensuring both accuracy and compliance. Together, these practices create a robust framework for handling healthcare data effectively.
Machine learning has turned data cleaning into a faster, more automated process, shedding the inefficiencies of manual methods. With AI-driven tools, real-time error detection can slash data inaccuracies by up to 60%, freeing healthcare professionals to dedicate more time to patient care instead of wrestling with data management. This shift addresses the long-standing challenges of manual data cleaning, which often consumed vast resources and left room for frequent errors in healthcare settings.
AI tools streamline data capture across multiple sources, flagging discrepancies before they escalate into operational challenges or compromise patient safety. These tools don’t just stop at automation - they continuously learn and adapt. By analyzing historical data, they refine validation processes to meet standards like HIPAA, reducing compliance risks and minimizing the chance of costly data breaches.
Take MedOps, for example. This platform demonstrates how machine learning can transform healthcare operations. With features like AI-powered insurance verification, real-time data validation, and tailored workflow automation, MedOps integrates seamlessly into existing systems, enhancing efficiency and reinforcing the streamlined workflows already in place.
As the healthcare sector braces for a projected shortage of 10 million health workers by 2030, AI-driven data cleaning is becoming essential. Organizations that embrace these technologies can avoid the pitfalls of slow decision-making, inaccurate reporting, and rising operational costs - issues that often plague manual data management systems.
Machine learning doesn’t just clean data; it lays the groundwork for better healthcare delivery, enabling professionals to focus on what truly matters: patient care.
Machine learning is transforming healthcare by improving the precision of data analysis. It can process massive amounts of information at incredible speeds, identifying subtle patterns that traditional methods often miss. Unlike older statistical models that stick to rigid assumptions, machine learning algorithms evolve and get smarter as they handle more data. This adaptability makes them particularly effective with complex and unstructured datasets.
Thanks to these strengths, machine learning offers sharper accuracy, uncovers hidden trends, and delivers dependable insights that aid in healthcare decisions. The result? Better diagnoses, more precise predictions, and streamlined data management that ultimately boosts patient care.
Machine learning brings some powerful tools to the table for managing missing data in healthcare records. Among these, deep learning-based imputation methods, like autoencoders, stand out. These techniques excel at predicting missing values by uncovering intricate patterns within the data. Another common approach is k-Nearest Neighbors (k-NN), along with multiple imputation methods, both of which are well-suited for handling diverse and high-dimensional healthcare datasets.
At their core, these methods estimate missing values using the available data, helping to preserve the dataset's overall integrity. By applying these techniques, healthcare organizations can enhance data quality and unlock more meaningful insights to guide their decisions.
Healthcare organizations can ensure HIPAA compliance when using AI-driven data cleaning tools like MedOps by adopting robust data protection measures. These include encrypting sensitive information, implementing strict access controls, and performing regular security audits to protect protected health information (PHI) effectively.
Organizations should also apply de-identification methods to strip out identifiable patient details wherever feasible. Establishing clear governance policies can further help mitigate risks such as data breaches or algorithmic bias. By keeping privacy and security at the forefront, compliance can be maintained throughout the AI integration process.