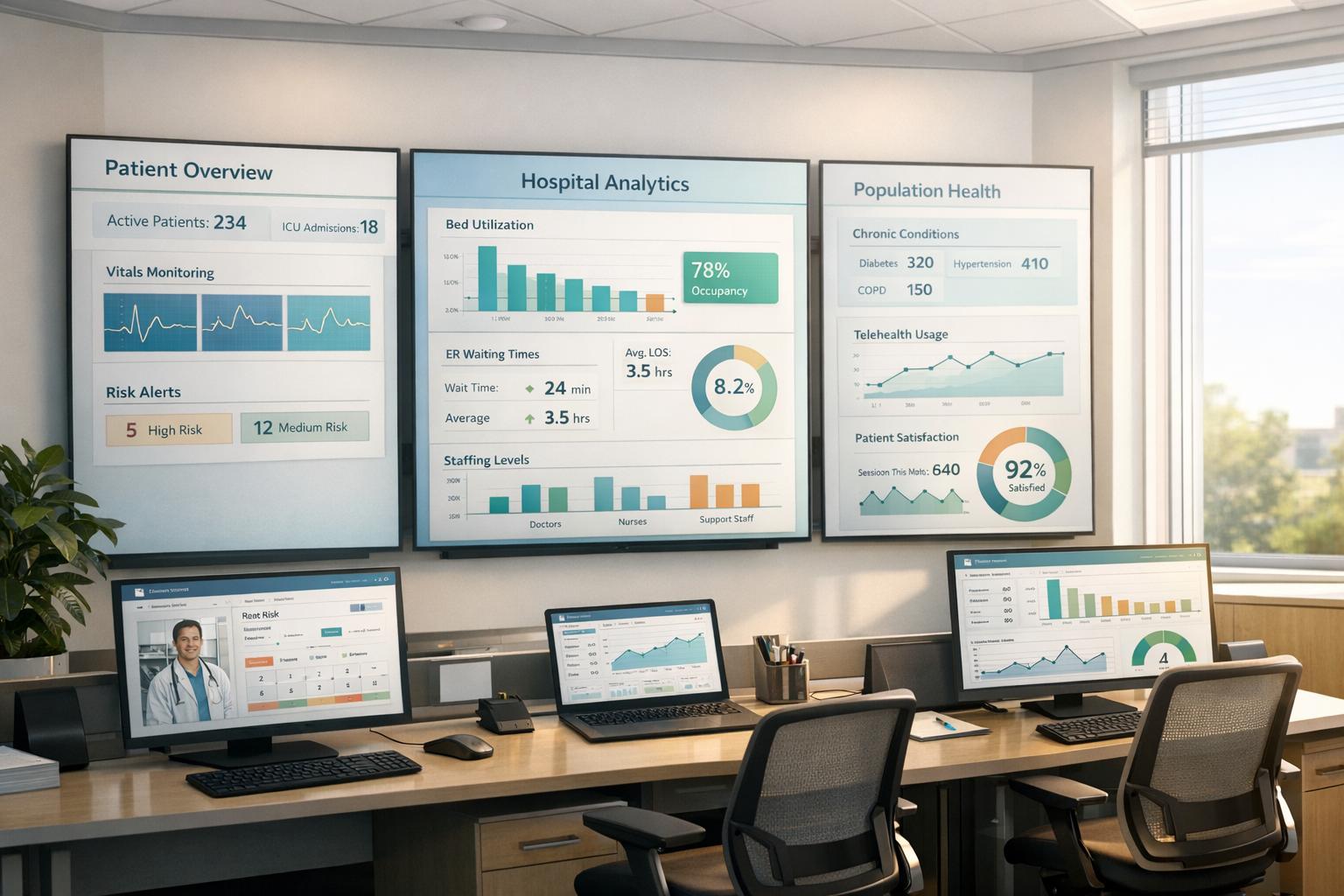
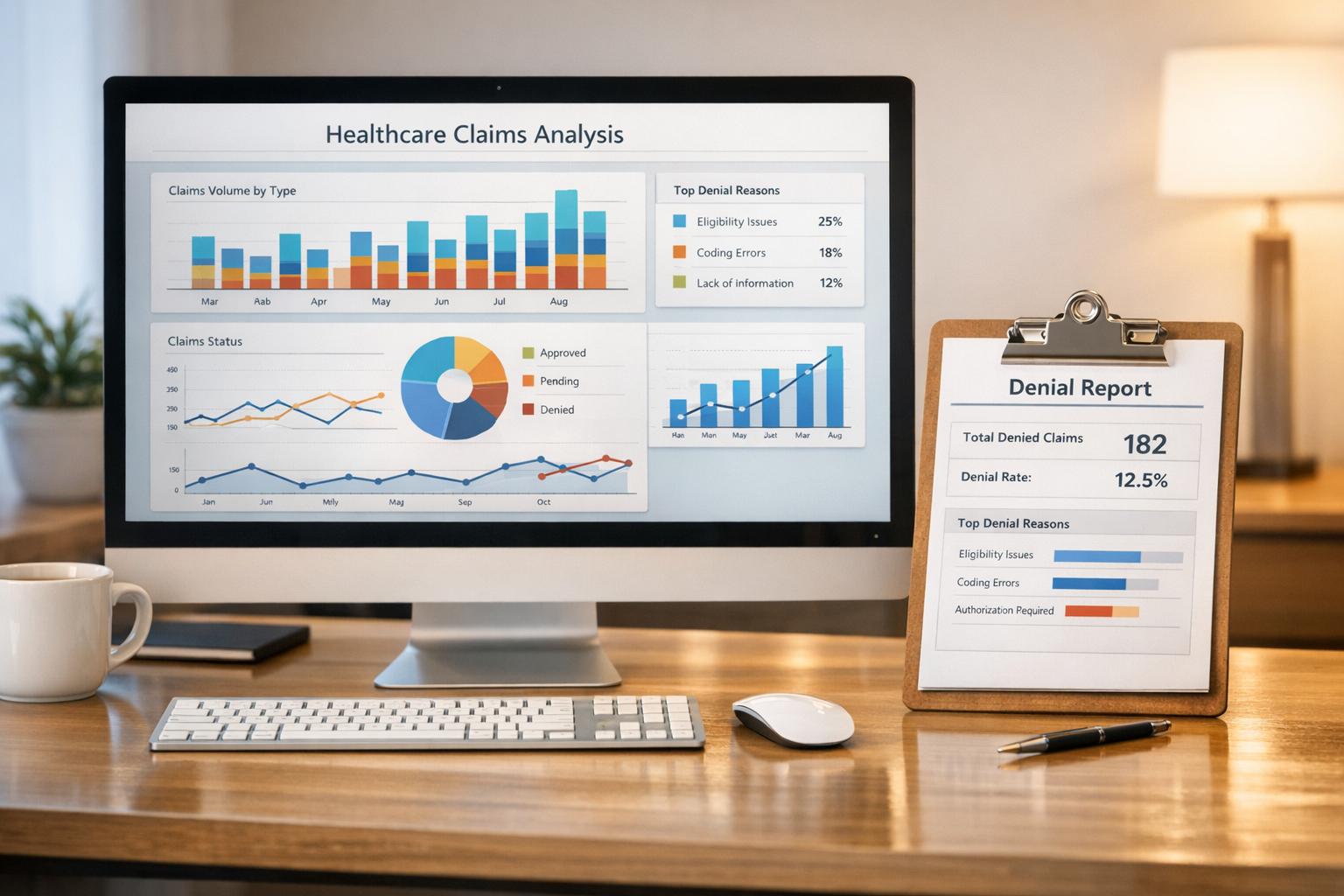
AI is revolutionizing healthcare eligibility verification by automating processes, improving accuracy, and ensuring compliance with privacy regulations.
AI is transforming healthcare eligibility checks by automating tedious manual processes, reducing errors, and saving time. Here's what you need to know:
AI is reshaping eligibility verification by combining speed, accuracy, and compliance, but organizations must prioritize privacy, fairness, and continual improvement to succeed.
Building effective AI models for healthcare eligibility verification depends on access to diverse, high-quality data. These models rely on such data to identify patterns, validate insurance coverage, and predict eligibility outcomes with accuracy.
Electronic Health Records (EHRs) are a key component in training eligibility AI. These digital records include a wealth of information like patient diagnoses, treatment histories, lab results, imaging studies, and doctor notes. However, using EHR data comes with challenges - about 80% of it is unstructured, such as free-text notes, which complicates its preparation for AI training.
Insurance claims data adds another crucial layer. This data includes historical claim submissions, patterns of approvals and denials, coverage verification results, and prior authorization decisions. By combining this with patient demographics - like age, location, and insurance plan details - AI models can better understand the intricate relationships between patient factors and eligibility outcomes.
Provider records supply information about healthcare facilities, practitioner credentials, network status, and billing trends. This allows AI systems to cross-reference patient coverage with provider details.
Since healthcare data is primarily collected for patient care, extensive preprocessing is required to transform clinical documentation into datasets suitable for AI training. These models demand large volumes of data to identify patterns and make accurate predictions.
Laboratory results and diagnostic data offer objective metrics tied to coverage requirements, while wearable device data contributes real-time health statistics that further refine eligibility decisions.
The demand for healthcare data is growing rapidly. By 2024, the U.S. market for de-identified health data is expected to exceed $8 billion, with projections reaching nearly $13.6 billion by 2030, reflecting an annual growth rate of about 9.1%.
Together, these varied data sources enable AI models to process complex medical information, all while adhering to stringent privacy standards.
Protecting patient privacy is not just an ethical obligation - it’s a legal one. Regulations like the Health Insurance Portability and Accountability Act (HIPAA) strictly govern how health data can be used in AI training.
De-identification is the process of removing the 18 HIPAA-defined identifiers from healthcare data, making it nearly impossible to trace the information back to an individual. This includes removing names, birth dates, Social Security numbers, and medical record numbers before the data is used for machine learning.
Healthcare organizations typically follow one of two methods for HIPAA-compliant de-identification. The Safe Harbor method ensures compliance by removing all 18 specific identifiers. While simple, this method can reduce the data's level of detail. The Expert Determination method, on the other hand, involves a statistician assessing the risk of re-identification and can retain more data utility, though it requires specialized expertise.
Even with these methods, de-identification is not foolproof. For example, in 1997, researcher Latanya Sweeney demonstrated how "de-identified" medical records could be re-linked to individuals.
Organizations developing AI models must exercise caution and thoroughly vet their data sources to avoid future legal or ethical issues if the legitimacy of their training data is questioned. After de-identification, maintaining HIPAA compliance remains essential. This includes documenting the de-identification process and implementing safeguards to protect the data throughout the model's lifecycle.
Before training AI models, healthcare data must go through a thorough process of cleaning, structuring, and standardizing. Andrew Ng, a prominent AI expert and founder of DeepLearning.AI, emphasizes the importance of this step:
"If 80 percent of our work is data preparation, then ensuring data quality is the most critical task for a machine learning team".
Poor data quality remains one of the leading reasons AI projects fail. In healthcare eligibility verification, this can have serious consequences, such as claim denials, delayed treatments, or compliance issues. In fact, research shows that high-quality data labels can improve model performance by as much as 30%.
The following steps ensure that datasets are ready for effective AI training.
Data cleaning tackles common problems in healthcare datasets, such as missing values, duplicates, formatting inconsistencies, and errors. This process ensures the AI model works with reliable and accurate information.
To ensure accuracy, teams cross-reference cleaned data with the original sources, verify that essential information is preserved during transformations, and document all changes for audit purposes.
After cleaning and standardizing the data, precise labeling is essential for training supervised AI models. This process involves converting historical claims into clear examples with specific outcomes, such as "approved", "denied", "requires prior authorization", or "pending additional documentation."
Healthcare systems rely on supervised and unsupervised learning to streamline eligibility verification processes. Each method comes with its own strengths and challenges, especially within the highly regulated landscape of U.S. healthcare. Choosing the right approach depends on factors like data availability, regulatory guidelines, and the desired outcomes for automation. These methods not only influence eligibility decisions but also play a role in enhancing compliance and operational efficiency.
Supervised learning is built around labeled datasets, where each input is paired with a known and correct output. This method often uses historical claims data with established outcomes to train AI models.
The training process involves exposing the model to thousands of examples where outcomes are already known. Experts carefully label datasets to ensure accuracy and reliability. The model then learns to identify patterns that guide eligibility decisions. For example, it might detect that certain insurance plans automatically approve specific procedures, while others require extra documentation. The model refines its predictions over time by analyzing labeled data.
One of the major advantages of supervised learning is its high accuracy and ease of validation. Since expected outcomes are known, healthcare providers can measure the model's performance against human reviewers. Supervised learning is particularly straightforward to validate because the desired output is pre-defined, and the baseline human performance is well-documented.
However, this method requires significant preparation. The demand for high-quality labeled datasets is growing rapidly across industries. In fact, the global market for data labeling is projected to grow from $1.5 billion in 2019 to $3.5 billion by 2024, with a CAGR of 18.5%. For healthcare, this means ensuring that labeling processes meet stringent quality standards. As Keymakr emphasizes:
"An accurate labeling process not only equips ML models with reliable information but also ensures that these models perform optimally in critical domains".
Despite its strengths, supervised learning has limitations. It cannot discover new patterns or insights beyond the scope of the training data, making it less effective for exploratory tasks.
Unsupervised learning takes a different approach by working with unlabeled data to uncover hidden patterns. Rather than predicting specific outcomes, it explores the underlying structure of data to reveal insights that might not be immediately obvious.
This method shines in complex scenarios, such as identifying rare or undiagnosed conditions. For eligibility verification, unsupervised models might group patients with similar characteristics, even if those patterns weren’t previously recognized. These algorithms analyze data to uncover relationships and features that may not be immediately apparent.
Unsupervised learning is particularly useful for organizations dealing with large amounts of unstructured data. Unlike supervised methods, it doesn’t rely on labeled datasets and can uncover complex, non-linear relationships that aren’t predefined. This flexibility is especially valuable in healthcare, where data is often messy and unpredictable.
Confidence in AI’s potential impact on healthcare is growing. A survey by Elsevier found that 72% of researchers and physicians believe AI will transform healthcare in the coming years.
However, there are challenges. Unsupervised algorithms can be harder to evaluate and explain, which can be problematic in healthcare settings that require clear audit trails for regulatory compliance. This lack of transparency can make it more difficult to ensure these models meet strict standards.
That said, research highlights the practical applications of unsupervised learning. For instance, a 2021 study by Antony et al. compared various unsupervised methods for predicting chronic kidney disease. Similarly, Vats et al. (2018) evaluated unsupervised techniques like DBSCAN, k-means, and Affinity Propagation for liver disease prediction, analyzing their accuracy and computational demands.
Both supervised and unsupervised methods align with HIPAA requirements, ensuring privacy through measures like data de-identification, encryption, and access restrictions.
Here’s a quick breakdown of the differences between these two approaches in the context of U.S. healthcare eligibility automation:
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled data (input and output known) | Unlabeled data (input without set output) |
| Human Intervention | High - requires expert labeling | Lower initially - needs later verification |
| Common Tasks | Prediction, classification, regression | Clustering, anomaly detection, pattern finding |
| Healthcare Applications | Disease diagnosis, patient outcome prediction | Patient grouping, anomaly detection |
| Accuracy | Generally higher due to labeled training | Varies based on validation methods |
| Computational Complexity | Moderate | High, especially with large datasets |
| Data Requirement | Extensive labeled datasets | Large volumes of unlabeled data |
| Examples of Algorithms | Decision trees, logistic regression, SVMs | K-means clustering, association rules (e.g., Apriori) |
Both methods come with their own strengths and limitations. The choice between supervised and unsupervised learning depends on the organization’s goals, available resources, and compliance needs. Many healthcare systems find that combining the two approaches provides the most effective solution for eligibility verification.
AI models designed for eligibility verification are constantly evolving, thanks to feedback loops and real-world data. This continuous improvement is essential in the ever-changing U.S. healthcare landscape, where regulations, insurance policies, and patient needs are in constant flux. By incorporating real-world feedback, these systems enhance their accuracy and adaptability, keeping pace with the industry's demands.
As Carter Happer explains:
"Feedback - either implicit (e.g., user behavior) or explicit (e.g., corrections, labels) - helps improve model performance, fosters user trust, and enhances system resilience. Importantly, it aligns human insight with machine learning, enabling models to evolve meaningfully over time."
Real-world feedback transforms AI systems into dynamic tools capable of adapting to new challenges. Each interaction with eligibility AI generates data that fine-tunes future predictions, ensuring the models stay aligned with updated insurance policies, regulatory changes, and emerging healthcare trends.
One effective approach involves provider feedback loops. Many U.S. healthcare systems now incorporate feedback mechanisms into provider dashboards. Clinicians can review AI predictions and provide corrections or confirmations, creating a cycle of continuous improvement. This process not only boosts the AI's accuracy but also builds trust among healthcare professionals. Over time, this iterative refinement enhances the precision of eligibility checks.
To support this process, healthcare organizations should prioritize user-friendly interfaces that allow providers to offer structured feedback easily. Additionally, continuous monitoring and analysis of aggregated feedback ensure that AI systems remain accurate and aligned with operational goals.
While continuous learning helps AI systems improve, it also introduces the risk of perpetuating biases, especially when new data reflects existing disparities. Regular monitoring is essential to identify and address unintended biases before they impact patient care. A striking example comes from a 2019 study by Obermeyer et al., which analyzed an AI risk prediction algorithm widely used in U.S. healthcare. The study examined data from 43,539 White patients and 6,079 Black patients (2013–2015) and revealed that the algorithm underestimated the needs of Black patients. Specifically, Black patients had 26.3% more chronic illnesses than White patients at the same risk score level (4.8 vs. 3.8 conditions). This bias stemmed from using healthcare costs as a proxy for illness severity, a method influenced by systemic barriers like reduced access to care.
To address this, researchers recalibrated the algorithm to use direct health indicators, such as chronic condition counts, instead of costs. This adjustment significantly improved equity, nearly tripling the enrollment of high-risk Black patients in care management programs - from 17.7% to 46.5%.
To prevent similar issues, healthcare organizations should implement robust methodologies for detecting and mitigating bias. Quality control systems, routine audits, and model validations can help ensure AI systems remain fair and effective across diverse patient populations.
Compliance is another critical concern. With 66% of healthcare practitioners expected to use AI by 2025 - up from 38% in 2023 - organizations face increasing pressure to balance innovation with regulatory adherence. The stakes are high: 92% of healthcare organizations experienced a cyberattack in the past year, with the average breach costing approximately $9.77 million. To safeguard electronic protected health information (ePHI), organizations must adopt technical safeguards like encryption, access controls, and audit trails.
Traditional HIPAA frameworks were not designed for the real-time decision-making capabilities of modern AI systems. This has prompted healthcare organizations to develop AI-specific policies and procedures. Despite the challenges, many healthcare executives emphasize the importance of adopting AI in a secure and responsible manner. These efforts not only enhance performance but also address critical issues of privacy and compliance, paving the way for further discussions on ethical considerations in eligibility AI.
The use of AI in healthcare eligibility brings up important concerns about privacy, compliance, and ethics. Healthcare data breaches are a growing problem, costing an average of $9.77 million per incident, with 81.2% of large-scale breaches in 2024 caused by hacking and IT issues. For organizations adopting AI systems, robust security measures are a must. Violating HIPAA regulations can result in penalties ranging from $141 to $2,134,831 per violation. Beyond financial costs, such missteps can erode patient trust.
The regulatory framework is also adapting to these challenges. Starting in January 2025, the Department of Health and Human Services (HHS) will require covered entities to conduct vulnerability scans every six months and annual penetration tests. Additionally, the Office for Civil Rights (OCR) has clarified that the HIPAA Security Rule applies to electronic PHI used in AI training data and algorithms created by regulated entities. This section explores how HIPAA compliance, data protection, and ethical practices intersect in the realm of eligibility AI.
HIPAA's Privacy Rule sets strict guidelines for how AI systems can access, use, and share protected health information (PHI). AI tools working with eligibility data must follow the minimum necessary standard, meaning they should only access the PHI required for their specific tasks.
Healthcare organizations have three main options for deploying HIPAA-compliant AI systems, each with its advantages and challenges:
| Option | Control Level | Implementation Effort |
|---|---|---|
| Self-Hosted Open-Source | Highest | High |
| HIPAA-Eligible Cloud LLM | Medium | Medium |
| Specialized AI Vendor | Lower | Low |
Self-hosting provides maximum control but requires significant technical expertise and investment. Cloud-based models offer scalability and managed services but need careful configuration to remain compliant. Specialized vendors provide ready-to-use solutions, though they may limit customization and come with higher costs.
To protect PHI, organizations should encrypt data during transit and at rest, enforce role-based access controls, and ensure only authorized personnel can access the system. It’s also critical to log all interactions involving PHI to maintain audit trails. Public AI models should never be used with PHI, and all AI outputs must be verified to ensure no PHI is inadvertently included.
Organizations working with third parties must establish Business Associate Agreements (BAAs), which legally bind them to HIPAA compliance. Before granting access to PHI, healthcare providers should verify the security measures of their AI technology partners. However, 67% of healthcare organizations are not yet ready for stricter AI security requirements expected in 2025.
Data de-identification is another way to protect privacy during AI training. Two methods can be used: the Safe Harbor approach, which removes 18 specific identifiers, or Expert Determination, which uses statistical techniques to minimize the risk of re-identification.
Technical safeguards alone aren't enough - AI systems must also be transparent in how they make decisions. This is essential for maintaining ethical accountability and ensuring healthcare providers can trust AI-driven eligibility determinations. Clear and understandable AI processes also enhance patient trust and improve the accuracy of eligibility verifications.
Recent regulations, such as the Algorithmic Accountability Act of 2022 and the European Union AI Act, now require organizations to evaluate AI systems for potential biases and discriminatory outcomes. To meet these standards, AI systems must prioritize explainability and interpretability. This means documenting not just the decisions AI tools make, but also how they arrive at those conclusions. Such documentation should detail the data included and excluded from AI models, along with the reasoning behind those choices. Sensitive or discriminatory data must be avoided to prevent biases and protect privacy rights.
Regular audits are essential to identify and address biases in AI predictions. These audits should assess the system’s performance across various demographic groups to ensure fair treatment. The FDA has also emphasized the importance of health equity in AI, defining bias as "systematic difference in treatment of certain objects, people, or groups in comparison to others".
Accountability frameworks play a crucial role in defining responsibilities for AI-driven decisions. These frameworks should clarify the roles of AI developers, healthcare providers, and the organizations implementing the technology. In hybrid decision-making processes where humans and AI work together, such frameworks are especially important for determining liability and ensuring proper oversight. Healthcare professionals also need training to use AI tools effectively, understanding both their strengths and limitations.
Patient consent processes should explicitly inform individuals about the use of AI in eligibility decisions, outlining both the potential benefits and risks. As Elizabeth Denham, Information Commissioner, has stated:
"The price of innovation does not need to be the erosion of fundamental privacy rights".
Data governance policies should guide how patient data is collected, stored, and used, ensuring anonymity and protection against breaches.
Transparency is also key to building trust. The Zendesk CX Trends Report 2024 emphasizes:
"Being transparent about the data that drives AI models and their decisions will be a defining element in building and maintaining trust with customers."
This transparency involves clear communication about AI system functions, accuracy, and limitations, enabling patients to make informed decisions about their care. Organizations must also maintain detailed records of bias detection, evaluation processes, and corrective actions to show their dedication to fairness and ongoing improvement.
AI-driven healthcare eligibility is undergoing a rapid transformation, with significant advancements expected over the next five years. The key to success lies in prioritizing high-quality data, safeguarding privacy, and adhering to ethical standards. The groundwork laid today will shape how effectively organizations can harness these technologies in the future.
AI adoption is picking up speed. According to PwC's October 2024 Pulse Survey, almost half (49%) of technology leaders reported that AI is now "fully integrated" into their core business strategies, and about one-third said it is embedded into their products and services. This trend shows no signs of slowing down, with 73% of executives planning to use generative AI to reshape their business models.
By 2025, regulatory frameworks are expected to become more adaptable, encouraging AI adoption while maintaining essential safeguards. However, compliance will remain a challenge. Currently, 67% of healthcare organizations report being unprepared for the stricter AI security standards anticipated in 2025. To stay ahead, organizations must take proactive steps to strengthen their compliance strategies.
Despite these challenges, leading platforms are finding ways to innovate while meeting regulatory demands. MedOps is at the forefront, using AI to streamline insurance verification and automate workflows. The platform addresses critical issues like data quality, privacy protection, bias reduction, and regulatory compliance, ensuring that human expertise and machine precision work together seamlessly.
Looking ahead, emerging trends point to even greater changes. Multimodal AI is extending its capabilities to process not just text but also audio and video data. Advances in hardware are boosting AI performance, while transparency and explainability remain vital priorities. Organizations that invest in robust AI governance today will be better equipped to leverage these developments.
The future of eligibility AI depends on balancing innovation with accountability. Workforce-related challenges, such as training and cultural shifts, remain significant hurdles, with 41% of executives citing these as key barriers to adopting generative AI. The organizations that succeed will be those that prepare their teams for a collaborative future where AI tools complement human decision-making, all while maintaining the highest standards of patient care and privacy.
AI transforms healthcare eligibility verification by processing vast amounts of data with high accuracy, cutting down on human errors and decreasing the chances of claim denials. Compared to manual methods, this results in quicker and more dependable outcomes.
On top of that, AI simplifies workflows by automating repetitive tasks, cutting administrative expenses, and enabling instant eligibility checks. This boosts efficiency, eliminates unnecessary delays, and creates a smoother experience for patients.
MedOps places a high priority on privacy and security when using AI for eligibility checks. Patient data is managed in full compliance with HIPAA regulations, guaranteeing the protection of sensitive information at all times. To achieve this, MedOps relies on secure cloud platforms that meet HIPAA standards and employs advanced encryption techniques to protect data during storage and transmission.
Data access is strictly limited to authorized personnel, ensuring tight control over who can handle sensitive information. Furthermore, MedOps collaborates exclusively with AI systems tailored for healthcare, ensuring patient privacy remains a top priority. These safeguards ensure that patient information is handled responsibly while enhancing the efficiency of eligibility processes.
Supervised learning depends on labeled data, where both the input and the desired output are clearly defined. This approach is particularly useful for tasks like determining patient eligibility or validating claims using historical records. The system learns by studying these examples and then applies what it has learned to new, similar situations.
Unsupervised learning, in contrast, deals with unlabeled data and focuses on discovering hidden patterns or clusters. In the context of healthcare eligibility, it can reveal trends, detect anomalies, or group patients in ways that aren't immediately apparent. Together, these methods are essential for creating smarter and more efficient AI tools in healthcare.